Example : Intermittency detection in decaying plasma turbulence simulation
For more details about the data, see Ha et al. (2024).
This example script can be found at aweSOM/examples/plasma-turbulence/plasma.ipynb.
To download the datasets used in this example, go to https://doi.org/10.5281/zenodo.13909411.
Single aweSOM realization
The example hdf5 file, features_2j1b1e0r_5000_jasym.h5, contains 4 features, \(j_{\parallel}\), \(j_{\rm asym}\), \(b_{\perp}\), and \(e_{\parallel}\). Place the hdf5 file inside the examples/plasma-turbulence/ directory and run the script.
To run a single SOM realization, use the examples/plasma-turbulence/run_plasma_som.py script with only one value for each argument.
cd examples/plasma-turbulence
python run_plasma_som.py --ratio 0.6 --alpha_0 0.1 --train 2097152
This will train a SOM realization with an initial learning rate \(\alpha_0 = 0.1\), a lattice ratio \(H = 0.6\), and \(N = 2097152\) training steps (the entire simulation domain, \(L^3 = 128^3\)).
Optional toggles inside the script can be modified as needed. file_name points to the hdf5 file containing the simulation snapshot, sampling_type can be either “uniform” (random initial weights between -1 and 1) or “sampling” (random initial weights sampled from the data), and merge_threshold sets the threshold of cost for merging two cluster centroids.
Two files will be generated: som_object.*.pkl and labels.*.npy. The former contains the trained SOM object and the latter contains the cluster IDs for each data point. You can visualize the results following this example Jupyter notebook.
Also included on Zenodo is the fiducial SOM realization shown in Ha et al. (2024) under som_object.fiducial-5000-64-37-0.1-2097152-1u.pkl.
Load object to analyze
[1]:
import aweSOM
from aweSOM import Lattice
import numpy as np
import matplotlib.pyplot as plt
import pickle
import os
path_to_object = aweSOM.__path__[0] + '/../../examples/plasma-turbulence/'
object_name = 'som_object.fiducial-5000-64-37-0.1-2097152-1u.pkl'
with open(path_to_object + object_name, 'rb') as f:
map = pickle.load(f)
xdim = map.xdim
ydim = map.ydim
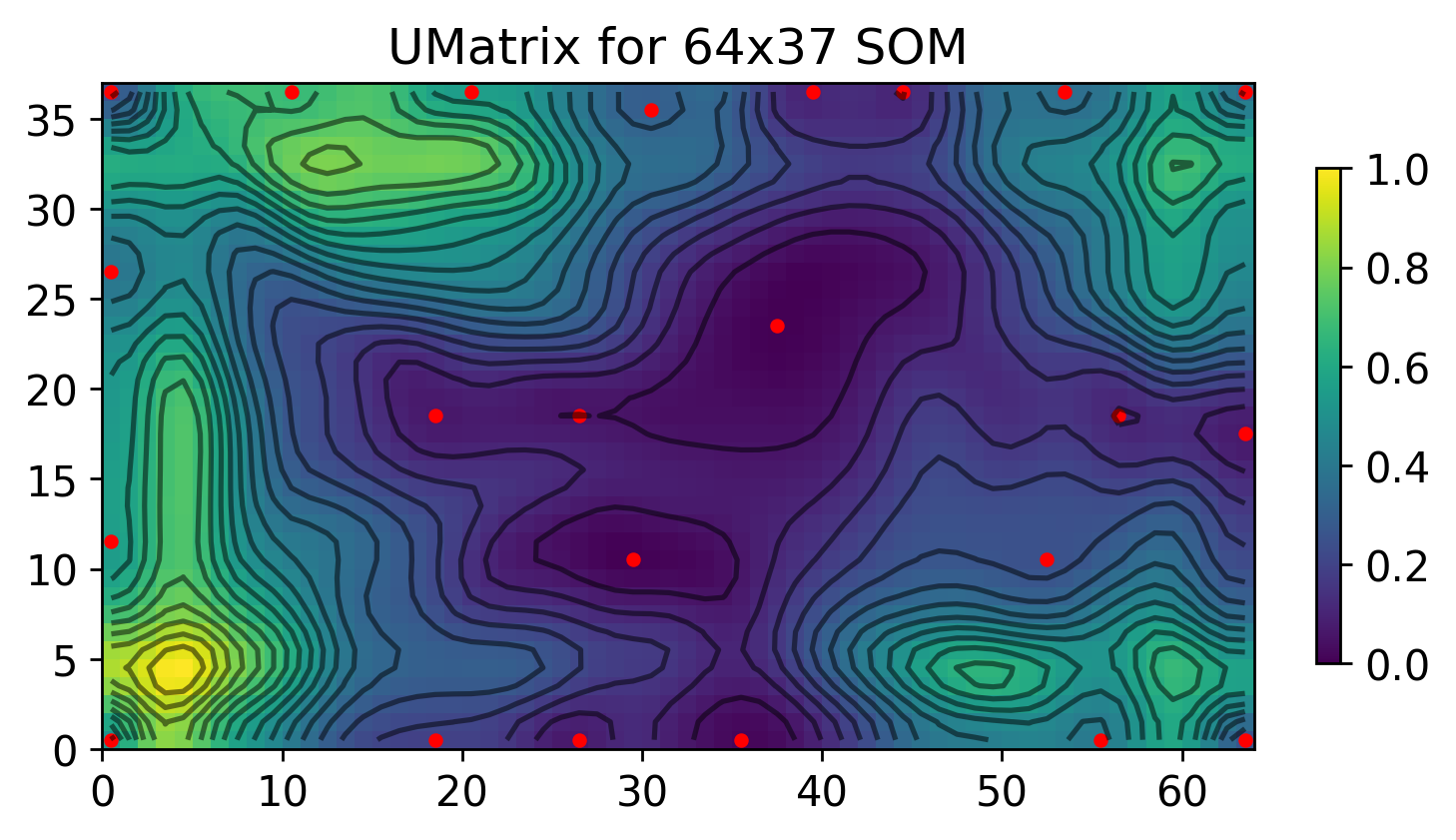
Visualize the U-matrix
[2]:
map.umat = map.compute_umat(smoothing=1)
unique_centroids = map.get_unique_centroids(map.compute_centroids())
unique_centroids['position_x'] = [x+0.5 for x in unique_centroids['position_x']]
unique_centroids['position_y'] = [y+0.5 for y in unique_centroids['position_y']]
X,Y = np.meshgrid(np.arange(xdim)+0.5, np.arange(ydim)+0.5)
plt.figure(dpi=250)
plt.pcolormesh(map.umat.T, cmap='viridis')
plt.scatter(unique_centroids['position_x'],unique_centroids['position_y'], color='red', s=10)
plt.colorbar(fraction=0.02)
plt.contour(X, Y, map.umat.T, levels=np.linspace(np.min(map.umat),np.max(map.umat), 20), colors='black', alpha=0.5)
plt.gca().set_aspect("equal")
plt.title(rf'UMatrix for {xdim}x{ydim} SOM')
print('Number of centroids:', len(unique_centroids['position_x']))
Number of centroids: 23
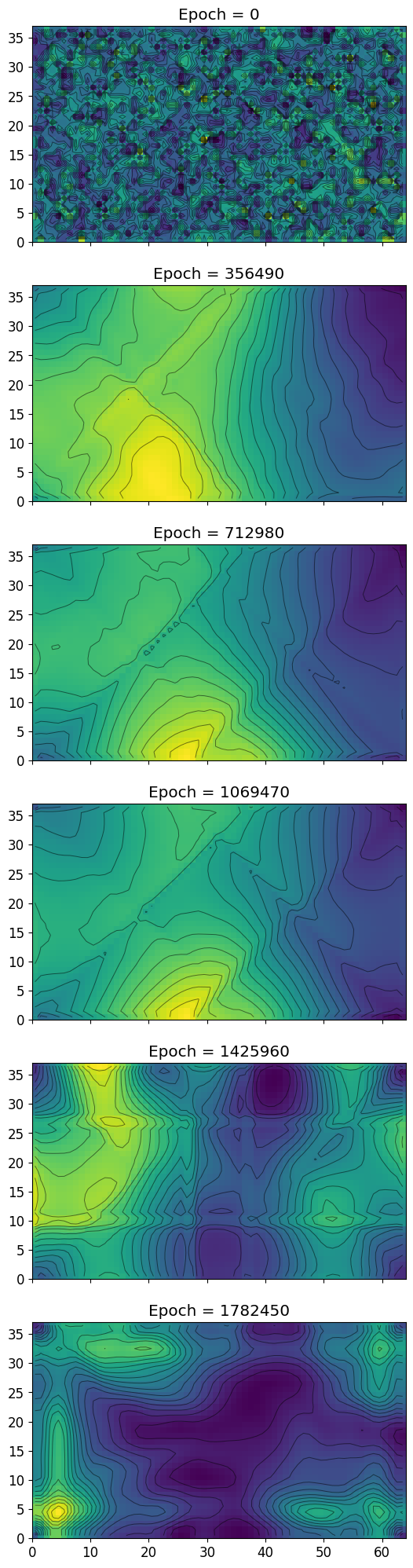
U-matrix history
[3]:
lattice_history = np.array(map.lattice_history)
umat_history = np.array(map.umat_history)
steps = np.linspace(0, lattice_history.shape[0] * map.save_frequency, lattice_history.shape[0], endpoint=False, dtype=int)
xdim = map.xdim
ydim = map.ydim
alpha_0 = map.alpha_0
train = map.train
X,Y = np.meshgrid(np.arange(xdim)+0.5, np.arange(ydim)+0.5)
num_plots = 6
fig, axs = plt.subplots(6, 1, figsize=(10, 25), sharex=True)
fig.subplots_adjust(hspace=0.2)
for i, k in enumerate(range(0, umat_history.shape[0], len(steps)//num_plots+1)):
umat = umat_history[k]
axs[i].title.set_text(f'Epoch = {steps[k]}')
mesh = axs[i].pcolormesh(umat.T, cmap='viridis')
axs[i].contour(X, Y, umat.T, levels=np.linspace(np.min(umat),np.max(umat), 20), colors='black', alpha=0.5, linewidths=0.7)
axs[i].set_aspect("equal")
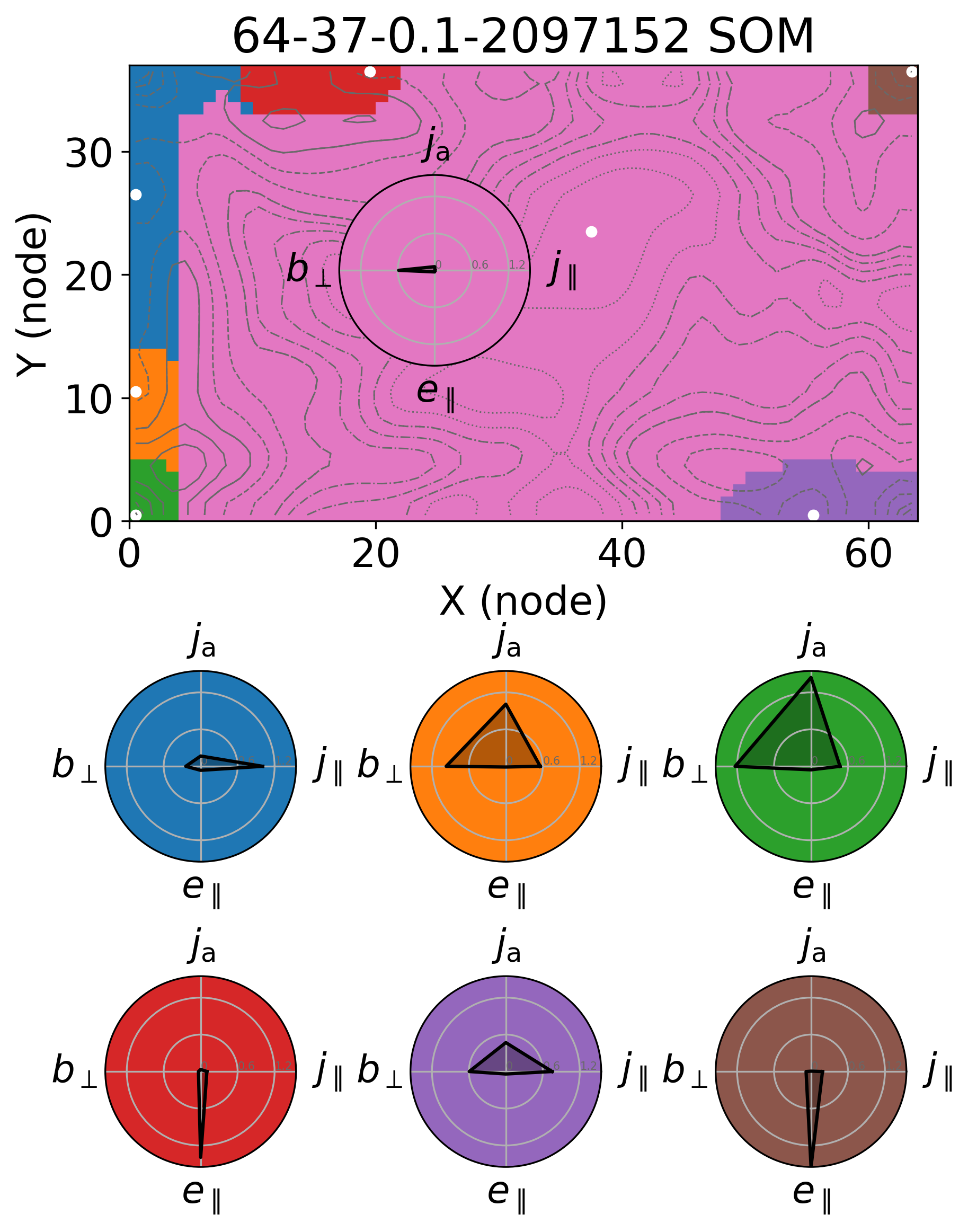
Spider plots to show the relative importance of each feature on the centroids of the identified clusters
[4]:
plt.rcParams['font.size'] = 18
def plot_centroid_spider(loaded_som_object : Lattice, smoothing : float = None, merge_cost : float = 0.2):
lattice_values = loaded_som_object.lattice
# normalize the lattice values around its mean
lattice_values = np.abs(lattice_values - lattice_values.mean(axis=0))
mod_lattice_values = np.hstack((lattice_values, lattice_values[:,0].reshape(-1,1)))
n_features = lattice_values.shape[1]
features = loaded_som_object.features_names
dict_lookup = {"j_mag" : r"$j$", "j_par" : r"$j_{\parallel}$", "j_perp" : r"$j_{\perp}$", "j_sym" : r"$j_{\rm s}$", "j_asym" : r"$j_{\rm a}$", "bz" : r"$b_z$", "b_perp" : r"$b_{\perp}$", "e_par" : r"$e_{\parallel}$", "e_perp" : r"$e_{\perp}$"}
angles = [n / float(n_features) * 2 * np.pi for n in range(n_features)]
angles += angles[:1]
loaded_som_object.umat = loaded_som_object.compute_umat(smoothing=smoothing)
naive_centroids = loaded_som_object.compute_centroids()
merged_centroids = loaded_som_object.merge_similar_centroids(naive_centroids, threshold=merge_cost)
unique_centroids = loaded_som_object.get_unique_centroids(merged_centroids)
unique_centroids_coord = {}
unique_centroids_coord['position_x'] = [x+0.5 for x in unique_centroids['position_x']]
unique_centroids_coord['position_y'] = [y+0.5 for y in unique_centroids['position_y']]
clusters = loaded_som_object.assign_cluster_to_lattice(smoothing=None,merge_cost=merge_cost)
# numbering_clusters = list(range(len(unique_centroids['position_x'])))
X,Y = np.meshgrid(np.arange(0,clusters.shape[0],1)+0.5, np.arange(0,clusters.shape[1],1)+0.5)
dx=10/3
umat = loaded_som_object.umat
fig, ax1 = plt.subplots(dpi=300,)
# ax1.axis('off')
plt.pcolormesh(clusters.T, cmap='tab10', clim=[0,10], rasterized=True)
# ax1.pcolormesh(umat.T, cmap='viridis')
plt.scatter(unique_centroids_coord['position_x'],unique_centroids_coord['position_y'], color='white', s=18)
# [plt.text(unique_centroids['position_x'][t]+1, unique_centroids['position_y'][t], numbering_clusters[t], color='k', fontsize=10) for t in range(len(numbering_clusters))]
ax1.contour(X, Y, umat.T, levels=np.linspace(np.min(umat),(np.mean(umat)+np.min(umat))/2, 4), alpha=1, linewidths=0.7, colors='dimgray', linestyles='dotted')
ax1.contour(X, Y, umat.T, levels=np.linspace((np.mean(umat)+np.min(umat))/2,np.mean(umat), 4), alpha=1, linewidths=0.7, colors='dimgray', linestyles='dashdot')
ax1.contour(X, Y, umat.T, levels=np.linspace(np.mean(umat),(np.max(umat)+np.mean(umat))/2, 4), alpha=1, linewidths=0.7, colors='dimgray', linestyles='dashed')
ax1.contour(X, Y, umat.T, levels=np.linspace((np.max(umat)+np.mean(umat))/2,np.max(umat), 4), alpha=1, linewidths=0.7, colors='dimgray', linestyles='solid')
ax1.set_aspect("equal")
ax1.set_title(f'{loaded_som_object.xdim}-{loaded_som_object.ydim}-{loaded_som_object.alpha_0}-{loaded_som_object.train} SOM')
# ax1.set_xticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
# ax1.set_yticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
ax1.set_xlabel('X (node)')
ax1.set_ylabel('Y (node)')
for centroid_id in range(len(unique_centroids['position_x'])):
row_values_of_centroids = [loaded_som_object.rowix(unique_centroids['position_x'][centroid_id], unique_centroids['position_y'][centroid_id])]
# nrow = 2
ncol = 3
pos_x = [0.07, 0.37, 0.67]
pos_y = [-0.25, -0.65, -1.05, -1.45, -1.85, -2.25]
# pos_x = [1.1, 1.4, 1.7]
# pos_y = [0.8, 0.3]
position_of_subplot = pos_x[centroid_id % ncol], pos_y[centroid_id // ncol], 0.25, 0.25
if centroid_id == 6:
position_of_subplot = 0.3, 0.4, 0.25, 0.25
ax2 = fig.add_axes(position_of_subplot, polar=True)
ax2.set_xticks(angles[:-1], [dict_lookup[feature] for feature in features], color='black', size=17)
ax2.set_rlabel_position(0)
ax2.set_yticks([0, 0.6, 1.2], ["0", "0.6", "1.2"], color="dimgray", size=5)
ax2.set_ylim(0.0,mod_lattice_values.max())
# ax2.set_yscale('log')
ax2.plot(angles, mod_lattice_values[row_values_of_centroids[0]], linewidth=1.5, linestyle='solid', color='black')
ax2.fill(angles, mod_lattice_values[row_values_of_centroids[0]], 'k', alpha=0.3)
ax2.set_facecolor(f'C{centroid_id}')
plt.show()
[5]:
merge_cost = 0.25
smoothing = None # a number or None (cannot be 0)
plot_centroid_spider(map, smoothing=smoothing, merge_cost=merge_cost)
Centroid A: (np.int64(39), np.int64(26)), count: 190
Centroid B: (np.int64(37), np.int64(23)), count: 376
Merging...
Centroid A: (np.int64(44), np.int64(35)), count: 40
Centroid B: (np.int64(39), np.int64(35)), count: 39
Merging...
Centroid A: (np.int64(25), np.int64(19)), count: 47
Centroid B: (np.int64(18), np.int64(18)), count: 400
Merging...
Centroid A: (np.int64(56), np.int64(18)), count: 100
Centroid B: (np.int64(63), np.int64(17)), count: 133
Merging...
Centroid A: (np.int64(35), np.int64(0)), count: 97
Centroid B: (np.int64(26), np.int64(0)), count: 55
Merging...
Centroid A: (np.int64(29), np.int64(10)), count: 259
Centroid B: (np.int64(35), np.int64(0)), count: 152
Merging...
Centroid A: (np.int64(49), np.int64(20)), count: 92
Centroid B: (np.int64(37), np.int64(23)), count: 566
Merging...
Centroid A: (np.int64(29), np.int64(10)), count: 411
Centroid B: (np.int64(37), np.int64(23)), count: 658
Merging...
Centroid A: (np.int64(44), np.int64(35)), count: 79
Centroid B: (np.int64(37), np.int64(23)), count: 1069
Merging...
Centroid A: (np.int64(18), np.int64(18)), count: 447
Centroid B: (np.int64(37), np.int64(23)), count: 1148
Merging...
Centroid A: (np.int64(48), np.int64(0)), count: 12
Centroid B: (np.int64(55), np.int64(0)), count: 36
Merging...
Centroid A: (np.int64(30), np.int64(35)), count: 56
Centroid B: (np.int64(37), np.int64(23)), count: 1595
Merging...
Centroid A: (np.int64(52), np.int64(10)), count: 72
Centroid B: (np.int64(63), np.int64(17)), count: 233
Merging...
Centroid A: (np.int64(0), np.int64(26)), count: 51
Centroid B: (np.int64(0), np.int64(19)), count: 22
Merging...
Centroid A: (np.int64(63), np.int64(0)), count: 19
Centroid B: (np.int64(55), np.int64(0)), count: 48
Merging...
Centroid A: (np.int64(63), np.int64(17)), count: 305
Centroid B: (np.int64(37), np.int64(23)), count: 1651
Merging...
Centroid A: (np.int64(53), np.int64(36)), count: 42
Centroid B: (np.int64(37), np.int64(23)), count: 1956
Merging...
Centroid A: (np.int64(0), np.int64(36)), count: 37
Centroid B: (np.int64(0), np.int64(26)), count: 73
Merging...
Centroid A: (np.int64(17), np.int64(0)), count: 74
Centroid B: (np.int64(37), np.int64(23)), count: 1998
Merging...
Centroid A: (np.int64(19), np.int64(36)), count: 26
Centroid B: (np.int64(10), np.int64(35)), count: 22
Merging...
Number of unique centroids: 7
Minimum cost between centroids: 0.2846310205754125
Centroid A: (np.int64(39), np.int64(26)), count: 190
Centroid B: (np.int64(37), np.int64(23)), count: 376
Merging...
Centroid A: (np.int64(44), np.int64(35)), count: 40
Centroid B: (np.int64(39), np.int64(35)), count: 39
Merging...
Centroid A: (np.int64(25), np.int64(19)), count: 47
Centroid B: (np.int64(18), np.int64(18)), count: 400
Merging...
Centroid A: (np.int64(56), np.int64(18)), count: 100
Centroid B: (np.int64(63), np.int64(17)), count: 133
Merging...
Centroid A: (np.int64(35), np.int64(0)), count: 97
Centroid B: (np.int64(26), np.int64(0)), count: 55
Merging...
Centroid A: (np.int64(29), np.int64(10)), count: 259
Centroid B: (np.int64(35), np.int64(0)), count: 152
Merging...
Centroid A: (np.int64(49), np.int64(20)), count: 92
Centroid B: (np.int64(37), np.int64(23)), count: 566
Merging...
Centroid A: (np.int64(29), np.int64(10)), count: 411
Centroid B: (np.int64(37), np.int64(23)), count: 658
Merging...
Centroid A: (np.int64(44), np.int64(35)), count: 79
Centroid B: (np.int64(37), np.int64(23)), count: 1069
Merging...
Centroid A: (np.int64(18), np.int64(18)), count: 447
Centroid B: (np.int64(37), np.int64(23)), count: 1148
Merging...
Centroid A: (np.int64(48), np.int64(0)), count: 12
Centroid B: (np.int64(55), np.int64(0)), count: 36
Merging...
Centroid A: (np.int64(30), np.int64(35)), count: 56
Centroid B: (np.int64(37), np.int64(23)), count: 1595
Merging...
Centroid A: (np.int64(52), np.int64(10)), count: 72
Centroid B: (np.int64(63), np.int64(17)), count: 233
Merging...
Centroid A: (np.int64(0), np.int64(26)), count: 51
Centroid B: (np.int64(0), np.int64(19)), count: 22
Merging...
Centroid A: (np.int64(63), np.int64(0)), count: 19
Centroid B: (np.int64(55), np.int64(0)), count: 48
Merging...
Centroid A: (np.int64(63), np.int64(17)), count: 305
Centroid B: (np.int64(37), np.int64(23)), count: 1651
Merging...
Centroid A: (np.int64(53), np.int64(36)), count: 42
Centroid B: (np.int64(37), np.int64(23)), count: 1956
Merging...
Centroid A: (np.int64(0), np.int64(36)), count: 37
Centroid B: (np.int64(0), np.int64(26)), count: 73
Merging...
Centroid A: (np.int64(17), np.int64(0)), count: 74
Centroid B: (np.int64(37), np.int64(23)), count: 1998
Merging...
Centroid A: (np.int64(19), np.int64(36)), count: 26
Centroid B: (np.int64(10), np.int64(35)), count: 22
Merging...
Number of unique centroids: 7
Minimum cost between centroids: 0.2846310205754125
Number of clusters : 7
Centroids: [(np.int64(0), np.int64(26)), (np.int64(0), np.int64(10)), (np.int64(0), np.int64(0)), (np.int64(19), np.int64(36)), (np.int64(55), np.int64(0)), (np.int64(63), np.int64(36)), (np.int64(37), np.int64(23))]
Map SOM result to data
[6]:
final_clusters = map.assign_cluster_to_lattice(smoothing=smoothing, merge_cost=merge_cost)
som_labels = map.assign_cluster_to_data(map.projection_2d, final_clusters)
Centroid A: (np.int64(39), np.int64(26)), count: 190
Centroid B: (np.int64(37), np.int64(23)), count: 376
Merging...
Centroid A: (np.int64(44), np.int64(35)), count: 40
Centroid B: (np.int64(39), np.int64(35)), count: 39
Merging...
Centroid A: (np.int64(25), np.int64(19)), count: 47
Centroid B: (np.int64(18), np.int64(18)), count: 400
Merging...
Centroid A: (np.int64(56), np.int64(18)), count: 100
Centroid B: (np.int64(63), np.int64(17)), count: 133
Merging...
Centroid A: (np.int64(35), np.int64(0)), count: 97
Centroid B: (np.int64(26), np.int64(0)), count: 55
Merging...
Centroid A: (np.int64(29), np.int64(10)), count: 259
Centroid B: (np.int64(35), np.int64(0)), count: 152
Merging...
Centroid A: (np.int64(49), np.int64(20)), count: 92
Centroid B: (np.int64(37), np.int64(23)), count: 566
Merging...
Centroid A: (np.int64(29), np.int64(10)), count: 411
Centroid B: (np.int64(37), np.int64(23)), count: 658
Merging...
Centroid A: (np.int64(44), np.int64(35)), count: 79
Centroid B: (np.int64(37), np.int64(23)), count: 1069
Merging...
Centroid A: (np.int64(18), np.int64(18)), count: 447
Centroid B: (np.int64(37), np.int64(23)), count: 1148
Merging...
Centroid A: (np.int64(48), np.int64(0)), count: 12
Centroid B: (np.int64(55), np.int64(0)), count: 36
Merging...
Centroid A: (np.int64(30), np.int64(35)), count: 56
Centroid B: (np.int64(37), np.int64(23)), count: 1595
Merging...
Centroid A: (np.int64(52), np.int64(10)), count: 72
Centroid B: (np.int64(63), np.int64(17)), count: 233
Merging...
Centroid A: (np.int64(0), np.int64(26)), count: 51
Centroid B: (np.int64(0), np.int64(19)), count: 22
Merging...
Centroid A: (np.int64(63), np.int64(0)), count: 19
Centroid B: (np.int64(55), np.int64(0)), count: 48
Merging...
Centroid A: (np.int64(63), np.int64(17)), count: 305
Centroid B: (np.int64(37), np.int64(23)), count: 1651
Merging...
Centroid A: (np.int64(53), np.int64(36)), count: 42
Centroid B: (np.int64(37), np.int64(23)), count: 1956
Merging...
Centroid A: (np.int64(0), np.int64(36)), count: 37
Centroid B: (np.int64(0), np.int64(26)), count: 73
Merging...
Centroid A: (np.int64(17), np.int64(0)), count: 74
Centroid B: (np.int64(37), np.int64(23)), count: 1998
Merging...
Centroid A: (np.int64(19), np.int64(36)), count: 26
Centroid B: (np.int64(10), np.int64(35)), count: 22
Merging...
Number of unique centroids: 7
Minimum cost between centroids: 0.2846310205754125
Number of clusters : 7
Centroids: [(np.int64(0), np.int64(26)), (np.int64(0), np.int64(10)), (np.int64(0), np.int64(0)), (np.int64(19), np.int64(36)), (np.int64(55), np.int64(0)), (np.int64(63), np.int64(36)), (np.int64(37), np.int64(23))]
Load simulation data to compare
You need two files for this step. First is the original hdf5 snapshot of the simulation, flds_5000.h5, second is the configuration file to read the snapshot, d3x128s10.ini. Put the .ini file inside aweSOM/examples/plasma-turbulence/, and the .h5 file inside a subfolder d3x128s10/.
Download the files from the Zenodo archive, then provide the path to the files with path.
[7]:
original_path = os.getcwd()
print('Current working directory:', original_path)
Current working directory: /mnt/home/tha10/git_repos/aweSOM/examples/plasma-turbulence
[8]:
import read_turbulence_data as rtd
conf = "d3x128s10.ini"
path = '/mnt/home/tha10/ceph/sim_snapshots/'# "/Users/tvh0021/Documents/Archive/"
filename = "flds_5000.h5"
lap = 5000
decay_turb = rtd.GetH5Data(path, filename, conf, lap)
# get the data
dx = 10./3.
decay_turb.return_basic_j_fields(dx)
decay_turb.return_all_other_fields()
/mnt/home/tha10/git_repos/aweSOM/examples/plasma-turbulence/initialize_turbulence.py:175: RuntimeWarning: divide by zero encountered in scalar divide
A = 0.1 * self.g0 / self.gammarad**2 # definition we use in Runko
d3x128s10
plotting j_par
flds
Visualize the SOM result vs. a xy-slice of the \(j_{\parallel}\).
[9]:
bx = decay_turb.bx
by = decay_turb.by
j_par = decay_turb.j_par
j_par_rms = np.sqrt(np.mean(j_par**2))
nx, ny, nz = decay_turb.nx, decay_turb.ny, decay_turb.nz
som_labels_transformed = som_labels.reshape((nz, ny, nx))
plt.rcParams.update({'font.size': 16})
slice_numbers = [27]
for slice_number in slice_numbers:
fig, ax = plt.subplots(2, 1, figsize=(10, 10), dpi=250, sharex=True)
fig.subplots_adjust(hspace=0.1)
jmag_plot = ax[0].pcolormesh(j_par[slice_number], cmap='RdBu', clim=[-1.5,1.5], rasterized=True)
fig.colorbar(jmag_plot, ax=ax[0], fraction=0.042, pad=0.05, label=r'$j_{\parallel}$', ticks=[-1.5, -1, -0.5, 0, 0.5, 1, 1.5], location="right")
# ax[0].contour(np.arange(0, nx)+0.5, np.arange(0, ny)+0.5, j_par[slice_number,:,:], levels=[-2.*j_par_rms,2.*j_par_rms], colors='green', linewidths=1, linestyles='solid')
ax[0].streamplot(np.arange(0, nx)+0.5, np.arange(0, ny)+0.5, bx[slice_number], by[slice_number], color='black', linewidth=0.25, broken_streamlines=False, density=1., integration_direction='both', arrowstyle='-|>', arrowsize=0.6, )
# fig.colorbar(eperp_plot, ax=ax[0], fraction=0.042, pad=0.04, label=r'$E_{\perp}$', ticks=[0, 0.1, 0.2, 0.3])
ax[0].set_aspect('equal', adjustable='box')
ax[0].grid()
# ax[0].set_xticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
ax[0].set_yticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
# ax[0].set_xlabel(r'x ($c/\omega_p$)')
ax[0].set_ylabel(r'y ($c/\omega_{\rm p}$)')
# ax[0].set_title(f'z = {slice_number*dx:.0f} '+ r'$c/\omega_{\rm p}$')
cluster_plot = ax[1].pcolormesh(som_labels_transformed[slice_number], cmap='tab10', clim=[0,10], rasterized=True)
cbar = fig.colorbar(cluster_plot, ax=ax[1], fraction=0.042, pad=0.05, label='Cluster', ticks=np.arange(0, len(set(som_labels)))+0.5, boundaries=np.arange(0, len(set(som_labels))+1), location="right")
cbar.ax.set_yticklabels(np.arange(0, len(set(som_labels))))
ax[1].contour(np.arange(0, nx)+0.5, np.arange(0, ny)+0.5, j_par[slice_number,:,:], levels=[-2.*j_par_rms,2.*j_par_rms], colors=['red','blue'], linewidths=1, linestyles='solid')
# ax[1].streamplot(np.arange(0, nx)+0.5, np.arange(0, ny)+0.5, bx[slice_number], by[slice_number], color='black', linewidth=0.25, broken_streamlines=False, density=1, integration_direction='both', arrowstyle='-|>', arrowsize=0.6, )
ax[1].set_aspect('equal', adjustable='box')
ax[1].grid()
ax[1].set_xticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
ax[1].set_yticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
ax[1].set_xlabel(r'x ($c/\omega_{\rm p}$)')
ax[1].set_ylabel(r'y ($c/\omega_{\rm p}$)')
plt.show()
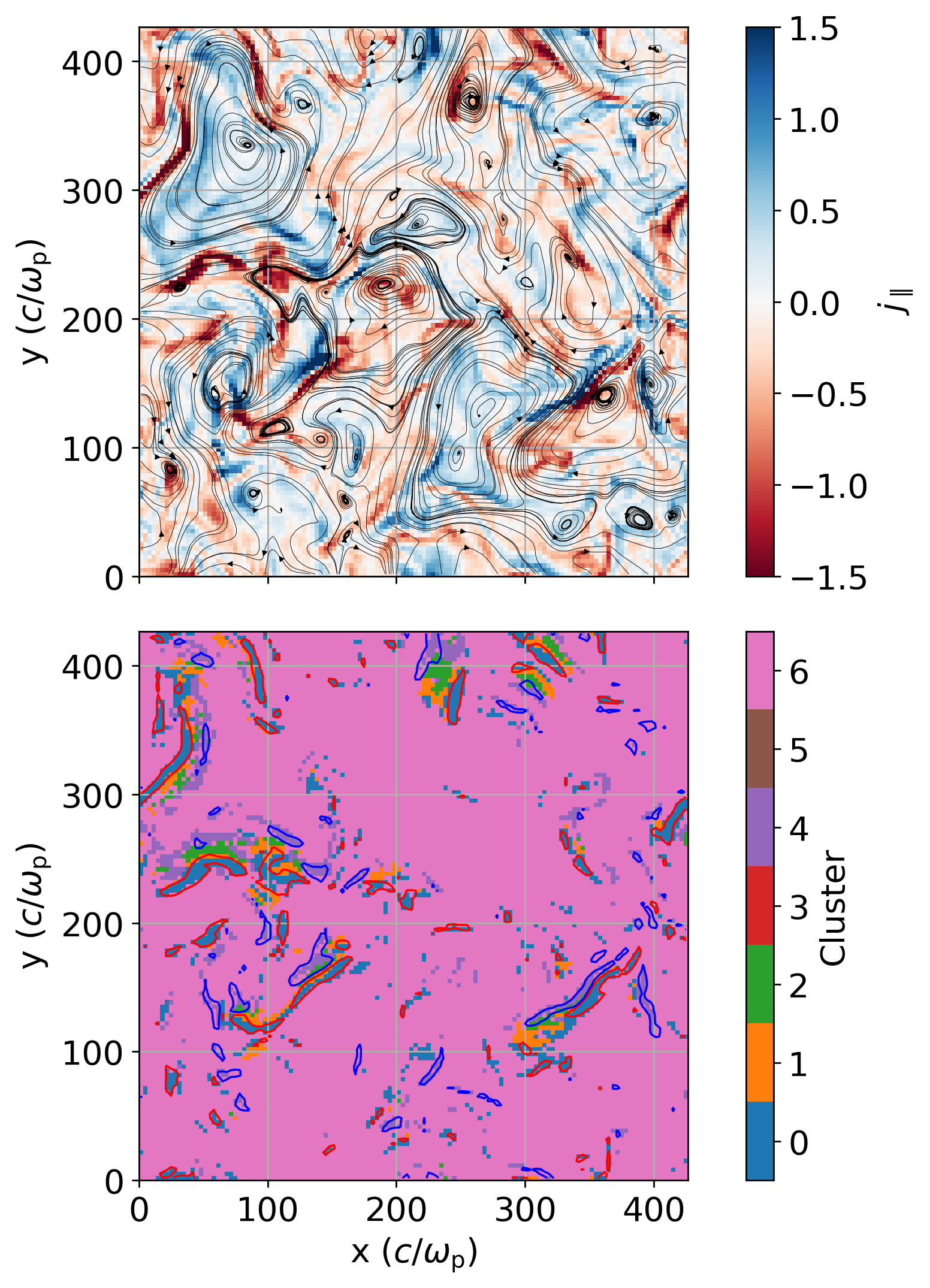
Visualize the different centroids and nodes by mapping the nodes value back into feature space
Obtain unique centroids after merger
[10]:
naive_centroids = map.compute_centroids()
merged_centroids = map.merge_similar_centroids(naive_centroids, threshold=merge_cost)
unique_centroids = map.get_unique_centroids(merged_centroids)
Centroid A: (np.int64(39), np.int64(26)), count: 190
Centroid B: (np.int64(37), np.int64(23)), count: 376
Merging...
Centroid A: (np.int64(44), np.int64(35)), count: 40
Centroid B: (np.int64(39), np.int64(35)), count: 39
Merging...
Centroid A: (np.int64(25), np.int64(19)), count: 47
Centroid B: (np.int64(18), np.int64(18)), count: 400
Merging...
Centroid A: (np.int64(56), np.int64(18)), count: 100
Centroid B: (np.int64(63), np.int64(17)), count: 133
Merging...
Centroid A: (np.int64(35), np.int64(0)), count: 97
Centroid B: (np.int64(26), np.int64(0)), count: 55
Merging...
Centroid A: (np.int64(29), np.int64(10)), count: 259
Centroid B: (np.int64(35), np.int64(0)), count: 152
Merging...
Centroid A: (np.int64(49), np.int64(20)), count: 92
Centroid B: (np.int64(37), np.int64(23)), count: 566
Merging...
Centroid A: (np.int64(29), np.int64(10)), count: 411
Centroid B: (np.int64(37), np.int64(23)), count: 658
Merging...
Centroid A: (np.int64(44), np.int64(35)), count: 79
Centroid B: (np.int64(37), np.int64(23)), count: 1069
Merging...
Centroid A: (np.int64(18), np.int64(18)), count: 447
Centroid B: (np.int64(37), np.int64(23)), count: 1148
Merging...
Centroid A: (np.int64(48), np.int64(0)), count: 12
Centroid B: (np.int64(55), np.int64(0)), count: 36
Merging...
Centroid A: (np.int64(30), np.int64(35)), count: 56
Centroid B: (np.int64(37), np.int64(23)), count: 1595
Merging...
Centroid A: (np.int64(52), np.int64(10)), count: 72
Centroid B: (np.int64(63), np.int64(17)), count: 233
Merging...
Centroid A: (np.int64(0), np.int64(26)), count: 51
Centroid B: (np.int64(0), np.int64(19)), count: 22
Merging...
Centroid A: (np.int64(63), np.int64(0)), count: 19
Centroid B: (np.int64(55), np.int64(0)), count: 48
Merging...
Centroid A: (np.int64(63), np.int64(17)), count: 305
Centroid B: (np.int64(37), np.int64(23)), count: 1651
Merging...
Centroid A: (np.int64(53), np.int64(36)), count: 42
Centroid B: (np.int64(37), np.int64(23)), count: 1956
Merging...
Centroid A: (np.int64(0), np.int64(36)), count: 37
Centroid B: (np.int64(0), np.int64(26)), count: 73
Merging...
Centroid A: (np.int64(17), np.int64(0)), count: 74
Centroid B: (np.int64(37), np.int64(23)), count: 1998
Merging...
Centroid A: (np.int64(19), np.int64(36)), count: 26
Centroid B: (np.int64(10), np.int64(35)), count: 22
Merging...
Number of unique centroids: 7
Minimum cost between centroids: 0.2846310205754125
Get the 1d position of the centroids with respect to a list of nodes
[11]:
centroid_rowids = np.empty((len(unique_centroids['position_x']), 2), dtype=int)
for centroid_id in range(len(unique_centroids['position_x'])):
row_values_of_centroids = [map.rowix(unique_centroids['position_x'][centroid_id], unique_centroids['position_y'][centroid_id])]
centroid_rowids[centroid_id,:] = [centroid_id,row_values_of_centroids[0]]
Get the clusters associated with each node in the lattice
[12]:
clusters = map.assign_cluster_to_lattice(smoothing=None,merge_cost=merge_cost)
Centroid A: (np.int64(39), np.int64(26)), count: 190
Centroid B: (np.int64(37), np.int64(23)), count: 376
Merging...
Centroid A: (np.int64(44), np.int64(35)), count: 40
Centroid B: (np.int64(39), np.int64(35)), count: 39
Merging...
Centroid A: (np.int64(25), np.int64(19)), count: 47
Centroid B: (np.int64(18), np.int64(18)), count: 400
Merging...
Centroid A: (np.int64(56), np.int64(18)), count: 100
Centroid B: (np.int64(63), np.int64(17)), count: 133
Merging...
Centroid A: (np.int64(35), np.int64(0)), count: 97
Centroid B: (np.int64(26), np.int64(0)), count: 55
Merging...
Centroid A: (np.int64(29), np.int64(10)), count: 259
Centroid B: (np.int64(35), np.int64(0)), count: 152
Merging...
Centroid A: (np.int64(49), np.int64(20)), count: 92
Centroid B: (np.int64(37), np.int64(23)), count: 566
Merging...
Centroid A: (np.int64(29), np.int64(10)), count: 411
Centroid B: (np.int64(37), np.int64(23)), count: 658
Merging...
Centroid A: (np.int64(44), np.int64(35)), count: 79
Centroid B: (np.int64(37), np.int64(23)), count: 1069
Merging...
Centroid A: (np.int64(18), np.int64(18)), count: 447
Centroid B: (np.int64(37), np.int64(23)), count: 1148
Merging...
Centroid A: (np.int64(48), np.int64(0)), count: 12
Centroid B: (np.int64(55), np.int64(0)), count: 36
Merging...
Centroid A: (np.int64(30), np.int64(35)), count: 56
Centroid B: (np.int64(37), np.int64(23)), count: 1595
Merging...
Centroid A: (np.int64(52), np.int64(10)), count: 72
Centroid B: (np.int64(63), np.int64(17)), count: 233
Merging...
Centroid A: (np.int64(0), np.int64(26)), count: 51
Centroid B: (np.int64(0), np.int64(19)), count: 22
Merging...
Centroid A: (np.int64(63), np.int64(0)), count: 19
Centroid B: (np.int64(55), np.int64(0)), count: 48
Merging...
Centroid A: (np.int64(63), np.int64(17)), count: 305
Centroid B: (np.int64(37), np.int64(23)), count: 1651
Merging...
Centroid A: (np.int64(53), np.int64(36)), count: 42
Centroid B: (np.int64(37), np.int64(23)), count: 1956
Merging...
Centroid A: (np.int64(0), np.int64(36)), count: 37
Centroid B: (np.int64(0), np.int64(26)), count: 73
Merging...
Centroid A: (np.int64(17), np.int64(0)), count: 74
Centroid B: (np.int64(37), np.int64(23)), count: 1998
Merging...
Centroid A: (np.int64(19), np.int64(36)), count: 26
Centroid B: (np.int64(10), np.int64(35)), count: 22
Merging...
Number of unique centroids: 7
Minimum cost between centroids: 0.2846310205754125
Number of clusters : 7
Centroids: [(np.int64(0), np.int64(26)), (np.int64(0), np.int64(10)), (np.int64(0), np.int64(0)), (np.int64(19), np.int64(36)), (np.int64(55), np.int64(0)), (np.int64(63), np.int64(36)), (np.int64(37), np.int64(23))]
Get the 1d position of the clusters with respect to a list of nodes
[13]:
clusters_rowix = np.empty((clusters.shape[0]*clusters.shape[1]), dtype=int)
for x in range(0, clusters.shape[0]):
for y in range(0, clusters.shape[1]):
clusters_rowix[map.rowix(x,y)] = clusters[x,y]
Plot the nodes on a 2d projection of normalized features
[14]:
plot_dimensions = (2,3) # 2d plot of the first two features
fig, ax = plt.subplots(1, 1, figsize=(10, 10), dpi=250)
fig.subplots_adjust(hspace=0.1)
# masked_labels = np.ma.masked_where(som_labels == 6, som_labels)
# scatter = ax.scatter(map.data_array[:, plot_dimensions[0]], map.data_array[:, plot_dimensions[1]],
# c=masked_labels, cmap='tab10', s=1, clim=[0, 10], rasterized=True, alpha=0.3)
ax.scatter(map.lattice[:, plot_dimensions[0]], map.lattice[:, plot_dimensions[1]], c=clusters_rowix, cmap="tab10", clim=[0,10], s=20, marker='o')
ax.scatter(map.lattice[centroid_rowids[:,1], plot_dimensions[0]], map.lattice[centroid_rowids[:,1], plot_dimensions[1]], c=centroid_rowids[:,0], cmap='tab10', clim=[0,10], s=80, edgecolors='black', linewidths=1, marker='*')
ax.set_xlabel(map.features_names[plot_dimensions[0]])
ax.set_ylabel(map.features_names[plot_dimensions[1]])
plt.show()
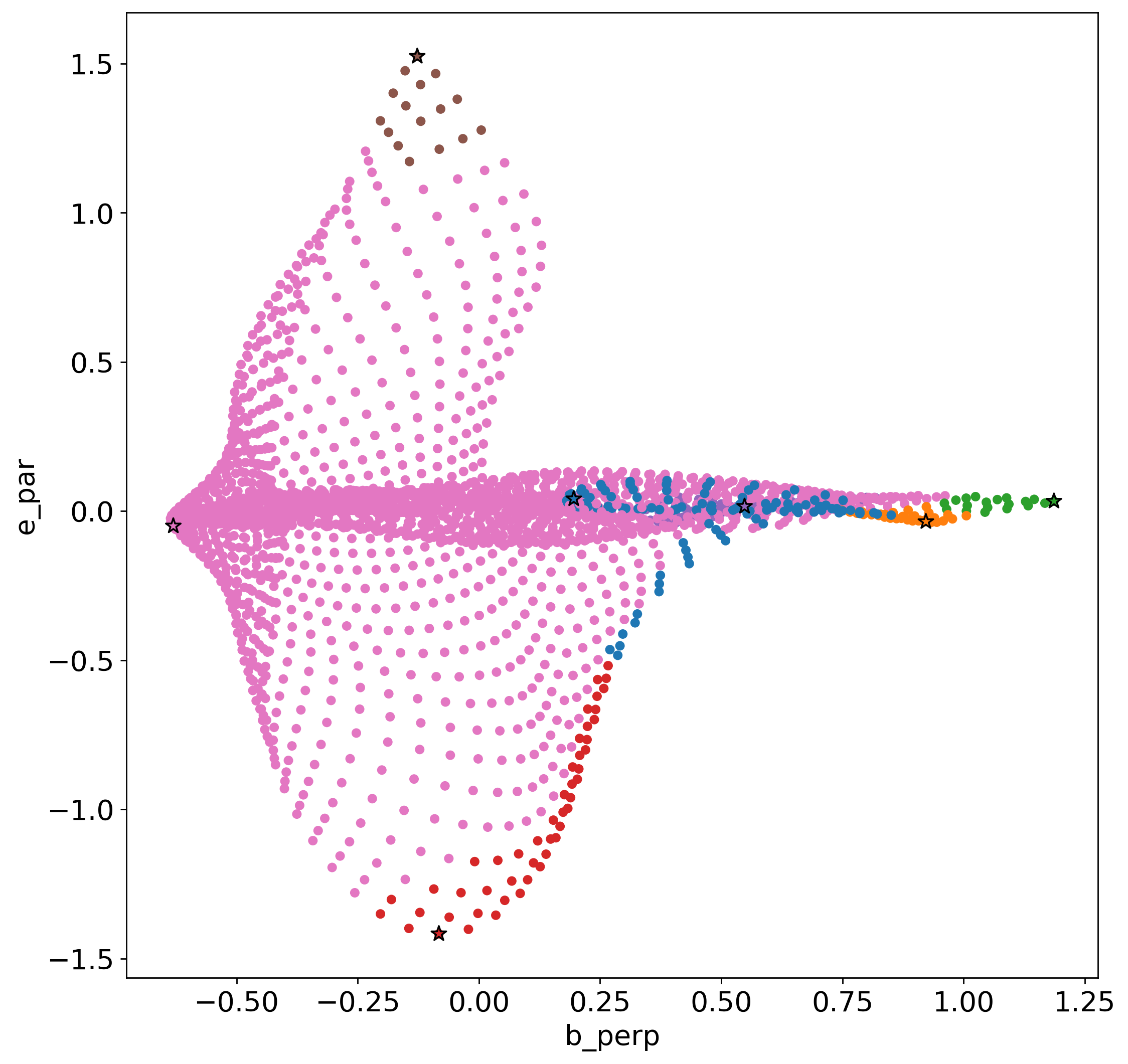
Convert the lattice values from a 2D (X*Y, f) array to a 3D array (X, Y, f)
[15]:
def make_2d_lattice(this_map: Lattice, lattice: np.ndarray, xdim: int, ydim: int) -> np.ndarray:
twod_lattice = np.empty((xdim, ydim, lattice.shape[1]))
for x in range(xdim):
for y in range(ydim):
twod_lattice[x,y,:] = lattice[this_map.rowix(x,y)]
return twod_lattice
[20]:
steps = np.linspace(0, lattice_history.shape[0] * map.save_frequency, lattice_history.shape[0], endpoint=False, dtype=int)
dict_lookup = {"j_mag" : r"$j$", "j_par" : r"$j_{\parallel}$", "j_perp" : r"$j_{\perp}$", "j_sym" : r"$j_{\rm s}$", "j_asym" : r"$j_{\rm a}$", "bz" : r"$b_z$", "b_perp" : r"$b_{\perp}$", "e_par" : r"$e_{\parallel}$", "e_perp" : r"$e_{\perp}$"}
num_plots = 9
fig, ax = plt.subplots(3, 3, figsize=(20, 20), sharex=True, sharey=True)
i = 0
for k in range(0, umat_history.shape[0], len(steps)//num_plots+1):
x,y = i // 3, i % 3
i += 1
twod_lattice = make_2d_lattice(map, map.lattice_history[k], map.xdim, map.ydim)
plot_dimensions = (0,1) # 2d plot of the first two features
for row in range(map.ydim):
ax[x,y].plot(twod_lattice[:,row,plot_dimensions[0]], twod_lattice[:,row,plot_dimensions[1]], color='k', marker=None, linewidth=0.5)
for column in range(map.xdim):
ax[x,y].plot(twod_lattice[column,:,plot_dimensions[0]], twod_lattice[column,:,plot_dimensions[1]], color='k', marker='o', markerfacecolor='r', markersize=2, linewidth=0.5)
# ax[x,y].text(0.9, 0.97, f'Epoch = {steps[k]}', horizontalalignment='center', verticalalignment='center', transform=ax[x,y].transAxes, fontsize=10)
ax[x,y].set_title(f'Epoch = {steps[k]}')
# ax.scatter(map.lattice[:, plot_dimensions[0]], map.lattice[:, plot_dimensions[1]], c=clusters_rowix, cmap="tab10", clim=[0,10], s=20, marker='o')
# ax.scatter(map.lattice[centroid_rowids[:,1], plot_dimensions[0]], map.lattice[centroid_rowids[:,1], plot_dimensions[1]], c=centroid_rowids[:,0], cmap='tab10', clim=[0,10], s=80, edgecolors='black', linewidths=1, marker='*')
if x == 2:
ax[x,y].set_xlabel(dict_lookup[map.features_names[plot_dimensions[0]]])
if y == 0:
ax[x,y].set_ylabel(dict_lookup[map.features_names[plot_dimensions[1]]])
# plt.show()
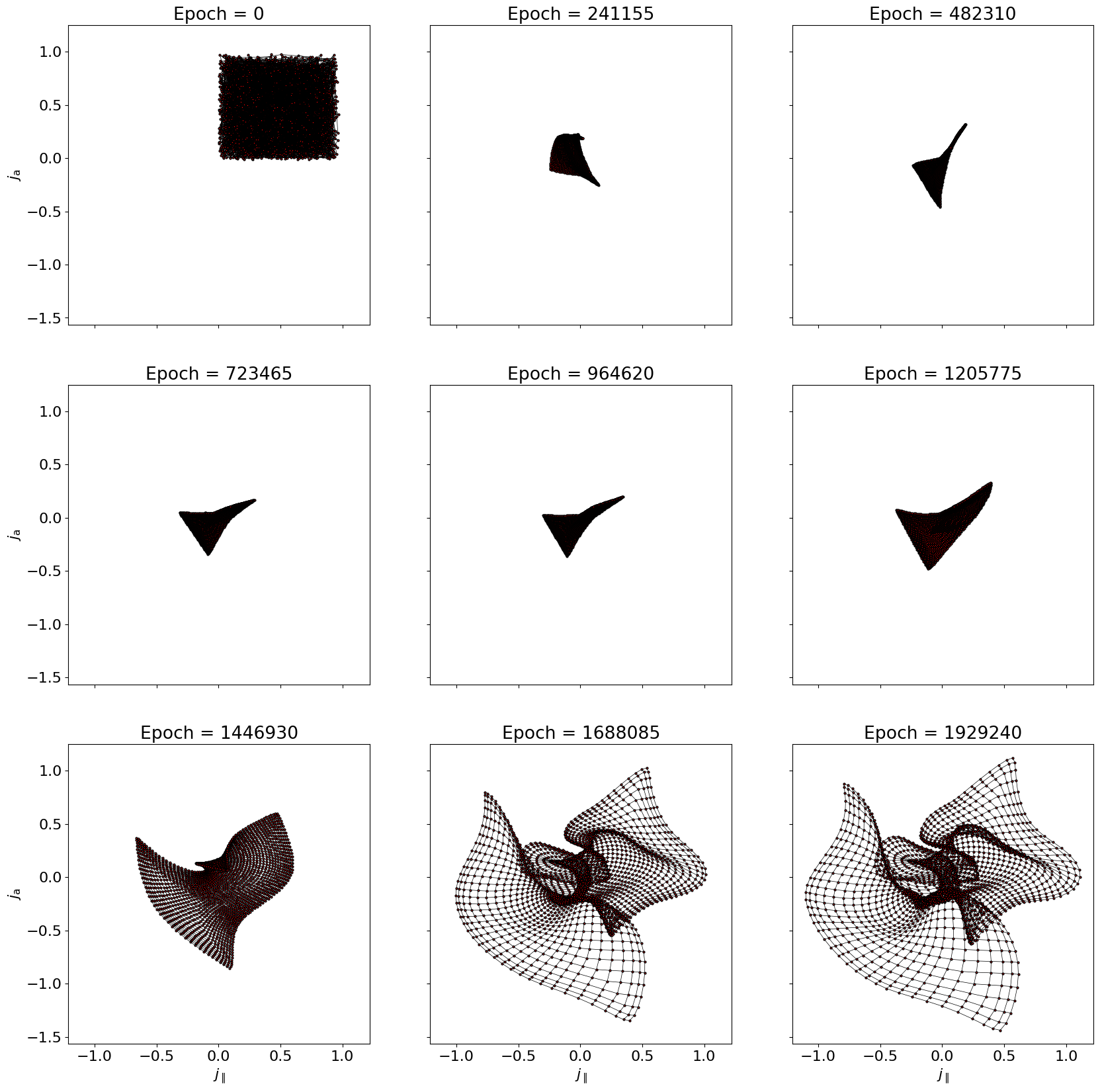
Triangle plots
[ ]:
import matplotlib.cm as cm
import matplotlib.patches as mpatches
colors_x = cm.plasma(np.linspace(0, 1, map.ydim))
colors_y = cm.copper(np.linspace(0, 1, map.xdim))
n_sample = 100000
sample_choice = np.random.choice(map.data_array.shape[0], n_sample, replace=False)
sample_data = map.data_array[sample_choice]
sample_label = som_labels[sample_choice]
exclude_cluster = 6
sample_data = sample_data[sample_label != exclude_cluster]
sample_label = sample_label[sample_label != exclude_cluster]
print("visualizing manual thr data")
fig2 = plt.figure(2, figsize=(20,20), dpi=300)
fig2.clear()
ic = 0
iplots = 0
nfea = len(map.features_names)
for jcomp in range(nfea):
for icomp in range(nfea):
ic += 1
# print("i {} j {}".format(icomp, jcomp))
#skip covariance with itself
if icomp == jcomp:
continue
#skip upper triangle
if icomp > jcomp:
continue
iplots += 1
ax = fig2.add_subplot(nfea, nfea, ic)
for row in range(map.ydim):
if row == 0 or row == map.ydim-1:
ax.plot(twod_lattice[:,row,icomp], twod_lattice[:,row,jcomp], color='k', marker=None, linewidth=1.5, zorder=2.5)
else:
ax.plot(twod_lattice[:,row,icomp], twod_lattice[:,row,jcomp], color='grey', marker=None, linewidth=0.5, zorder=2)
# for column in range(map.xdim):
# if column == 0 or column == map.xdim-1 or column == map.xdim//2:
# ax.plot(twod_lattice[column,:,icomp], twod_lattice[column,:,jcomp], color=colors_y[column], linestyle='-.', marker=None, linewidth=1)
scatter = ax.scatter(map.lattice[:,icomp], map.lattice[:,jcomp], c=clusters_rowix, cmap="tab10", clim=[0,10], s=3, marker='s')
ax.scatter(map.lattice[centroid_rowids[:,1], icomp], map.lattice[centroid_rowids[:,1], jcomp], c=centroid_rowids[:,0], cmap='tab10', clim=[0,10], s=50, edgecolors='black', linewidths=1, marker='*', zorder=3)
ax.scatter(sample_data[:,icomp], sample_data[:,jcomp], c=sample_label, cmap="tab10", s=2, marker='o', alpha=0.3, clim=[0,10], edgecolors='none')
ax.set_xlim(-2.5,2.5)
ax.set_ylim(-2.5,2.5)
ax.set_xticks([-2,-1,0,1,2])
# ax.set_xticklabels([-2,-1,0,1,2])
# ax.grid()
ax.axhline(0, color='black', linestyle='--', linewidth=0.5)
ax.axvline(0, color='black', linestyle='--', linewidth=0.5)
if jcomp == nfea-1:
ax.set_xlabel('{}'.format(dict_lookup[map.features_names[icomp]]))
else:
ax.set_xticks([])
if icomp == 0:
ax.set_ylabel('{}'.format(dict_lookup[map.features_names[jcomp]]))
else:
ax.set_yticks([])
fig2.suptitle(f"Triangle plots of SOM projections", x=0.4, y=0.7, fontsize=20)
# fig2.text(0.7, 0.7, '* : cluster centroids', ha='right', va='top', fontsize=12, color='black', transform=fig2.transFigure)
fig2.subplots_adjust(right=0.88)
cbar_ax = fig2.add_axes([0.7, 0.1, 0.02, 0.6])
cbar = fig2.colorbar(scatter, cax=cbar_ax, ticks=np.arange(0, len(set(som_labels)))+0.5, boundaries=np.arange(0, len(set(som_labels))+1))
cbar.ax.set_yticklabels(np.arange(0, len(set(som_labels))))
cbar.set_label("Cluster ID")
# fig2.savefig('/mnt/home/tha10/jupyter-notebooks/som_triangle.pdf')
visualizing manual thr data
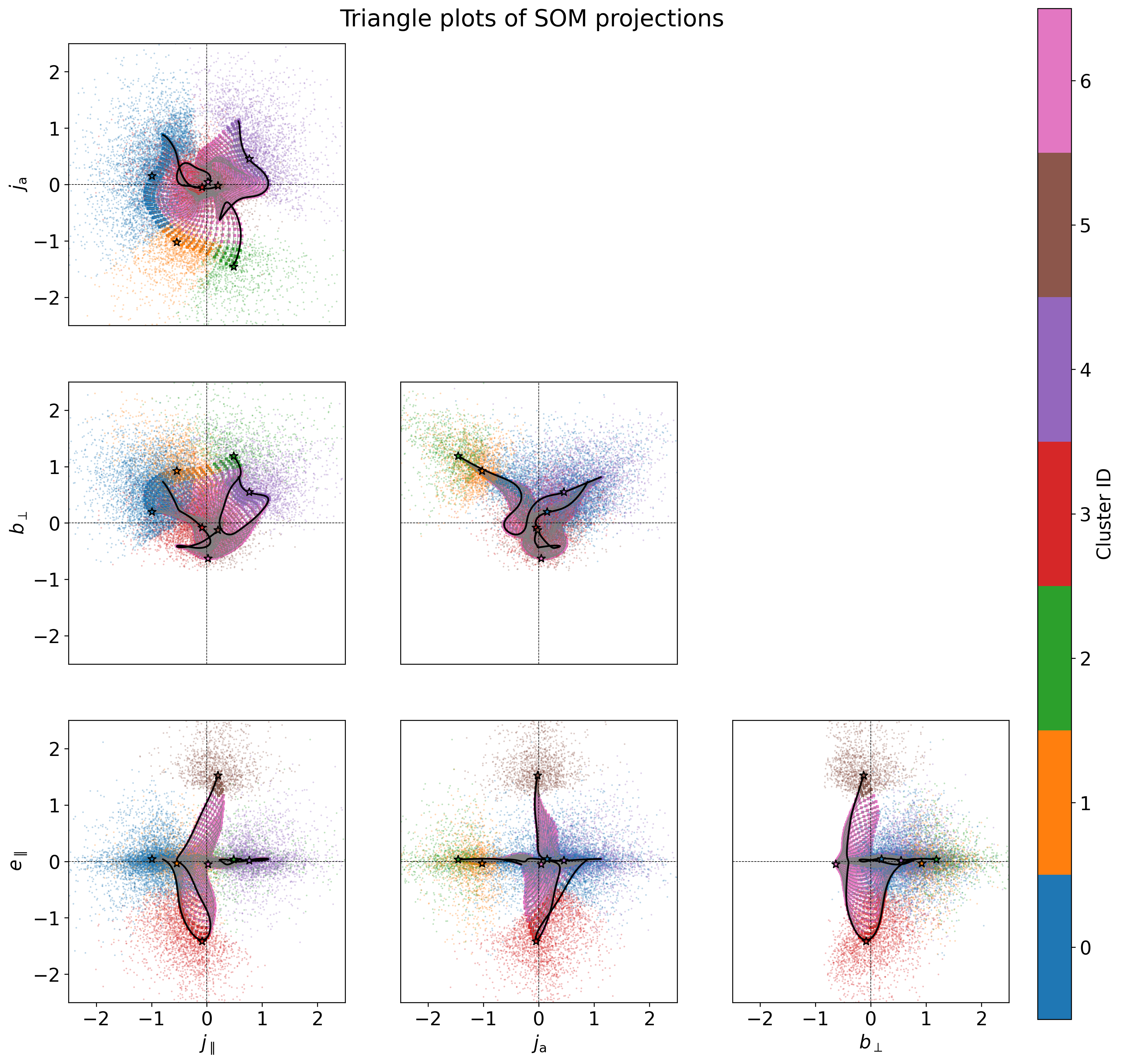
Stacking multiple aweSOM realizations for SCE analysis
To run a set of SOM realizations, use the examples/plasma-turbulence/run_plasma_som.py script with multiple values for each argument. run_plasma_som.py uses the multiprocessing package, so the more cores available, the faster it should run.
You will also need the file features_2j1b1e0r_5000_jasym.h5 from the Zenodo archive.
cd examples/plasma-turbulence
python run_plasma_som.py --ratio 0.6 0.8 1. --alpha_0 0.1 0.2 0.4 --train 1000000 2097152 4194304
Refer to examples/slurm_scripts/submit_plasma.slurm for an example of the SLURM submit script to run the parameter scan on a set of aweSOM realizations.
The result of this run is a list of files with names labels.* and som_object.*. The labels are final clustering results, while the objects are pickle files of the entire trained lattice that can be modified. Move all labels.* files into a subfolder named som_results.
Alternatively, you can use a set of pre-trained aweSOM realizations, which can be retrieved from the Zenodo archive, under plasma-som-realizations.tar. Unpack the files inside aweSOM/examples/plasma-turbulence/som_results/.
[ ]:
original_path = os.getcwd()
print('Current working directory:', original_path)
Current working directory: /mnt/home/tha10/git_repos/aweSOM/examples/plasma-turbulence
[ ]:
import read_turbulence_data as rtd
conf = "d3x128s10.ini"
path = '/mnt/home/tha10/ceph/sim_snapshots/'# "/Users/tvh0021/Documents/Archive/"
filename = "flds_5000.h5"
lap = 5000
decay_turb = rtd.GetH5Data(path, filename, conf, lap)
# get the data
dx = 10./3.
decay_turb.return_basic_j_fields(dx)
decay_turb.return_all_other_fields()
d3x128s10
plotting j_par
flds
/mnt/home/tha10/git_repos/aweSOM/examples/plasma-turbulence/initialize_turbulence.py:175: RuntimeWarning: divide by zero encountered in scalar divide
A = 0.1 * self.g0 / self.gammarad**2 # definition we use in Runko
To run the SCE clustering, import cuda to use GPU acceleration. GPU is not necessary for the Iris dataset but is absolutely necessary here (\(N_{\rm iris} = 150\), \(N_{\rm plasma} = 128^3\)).
Run the SCE \(G_{\rm sum}\) calculation with:
cd som_results
python [path_to_aweSOM]/aweSOM/src/aweSOM/sce.py --subfolder SCE --dims 2097152
Make sure that the first line of output is Using JAX for GPU computation.
Refer to examples/slurm_scripts/submit.gpu for an example of the SLURM submit script to run the SCE analysis on a set of aweSOM realizations.
Using one NVIDIA V-100 GPU, this should not take more than 3 minutes to complete. All cluster masks and multimap_mappings.txt are saved in SCE/
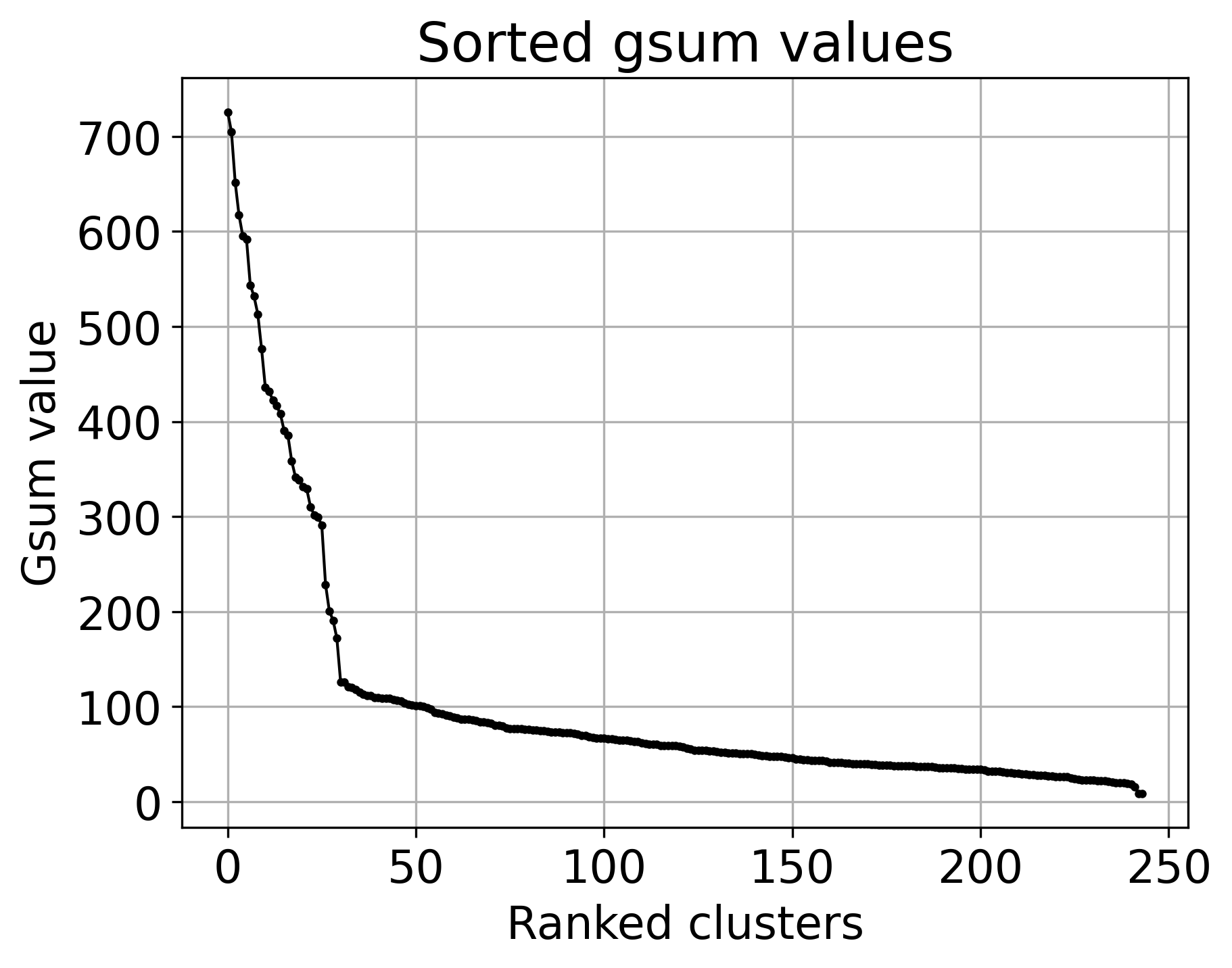
Now visualize \(G_{\rm sum}\)
[ ]:
os.chdir(original_path) # recover the original path
file_path = 'som_results/SCE/'
file_name = 'multimap_mappings.txt'
from aweSOM.make_sce_clusters import get_gsum_values, plot_gsum_values
ranked_gsum_list, map_list = get_gsum_values(file_path+file_name)
plot_gsum_values(ranked_gsum_list)
In the simplest case, add all gsum values together to obtain final SCE clustering result
[ ]:
number_of_points = int(128**3)
sce_sum = np.zeros((number_of_points))
for i in range(len(ranked_gsum_list)):
current_cluster_mask = np.load(f"{file_path}/mask-{map_list[i][2]}-id{map_list[i][1]}.npy")
sce_sum += current_cluster_mask
Visualize the SCE stacking result
[ ]:
sce_sum_transformed = sce_sum.reshape((128,128,128))
slice_numbers = [27]
for slice_number in slice_numbers:
fig, ax = plt.subplots(2, 1, figsize=(10, 10), dpi=250, sharex=True)
fig.subplots_adjust(hspace=0.1)
jmag_plot = ax[0].pcolormesh(j_par[slice_number], cmap='RdBu', clim=[-1.5,1.5], rasterized=True)
fig.colorbar(jmag_plot, ax=ax[0], fraction=0.042, pad=0.05, label=r'$j_{\parallel}$', ticks=[-1.5, -1, -0.5, 0, 0.5, 1, 1.5], location="right")
# ax[0].contour(np.arange(0, nx)+0.5, np.arange(0, ny)+0.5, j_par[slice_number,:,:], levels=[-2.*j_par_rms,2.*j_par_rms], colors='green', linewidths=1, linestyles='solid')
ax[0].streamplot(np.arange(0, nx)+0.5, np.arange(0, ny)+0.5, bx[slice_number], by[slice_number], color='black', linewidth=0.25, broken_streamlines=False, density=1., integration_direction='both', arrowstyle='-|>', arrowsize=0.6, )
# fig.colorbar(eperp_plot, ax=ax[0], fraction=0.042, pad=0.04, label=r'$E_{\perp}$', ticks=[0, 0.1, 0.2, 0.3])
ax[0].set_aspect('equal', adjustable='box')
ax[0].grid()
# ax[0].set_xticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
ax[0].set_yticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
# ax[0].set_xlabel(r'x ($c/\omega_p$)')
ax[0].set_ylabel(r'y ($c/\omega_{\rm p}$)')
# ax[0].set_title(f'z = {slice_number*dx:.0f} '+ r'$c/\omega_{\rm p}$')
cluster_plot = ax[1].pcolormesh(sce_sum_transformed[slice_number], cmap='Greys_r', rasterized=True)
cbar = fig.colorbar(cluster_plot, ax=ax[1], fraction=0.042, pad=0.05, label='SCE signal strength', location="right")
# cbar.ax.set_yticklabels(np.arange(0, len(set(som_labels))))
ax[1].contour(np.arange(0, nx)+0.5, np.arange(0, ny)+0.5, j_par[slice_number,:,:], levels=[-2.*j_par_rms,2.*j_par_rms], colors=['red','blue'], linewidths=1, linestyles='solid')
# ax[1].streamplot(np.arange(0, nx)+0.5, np.arange(0, ny)+0.5, bx[slice_number], by[slice_number], color='black', linewidth=0.25, broken_streamlines=False, density=1, integration_direction='both', arrowstyle='-|>', arrowsize=0.6, )
ax[1].set_aspect('equal', adjustable='box')
ax[1].grid()
ax[1].set_xticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
ax[1].set_yticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
ax[1].set_xlabel(r'x ($c/\omega_{\rm p}$)')
ax[1].set_ylabel(r'y ($c/\omega_{\rm p}$)')
plt.show()
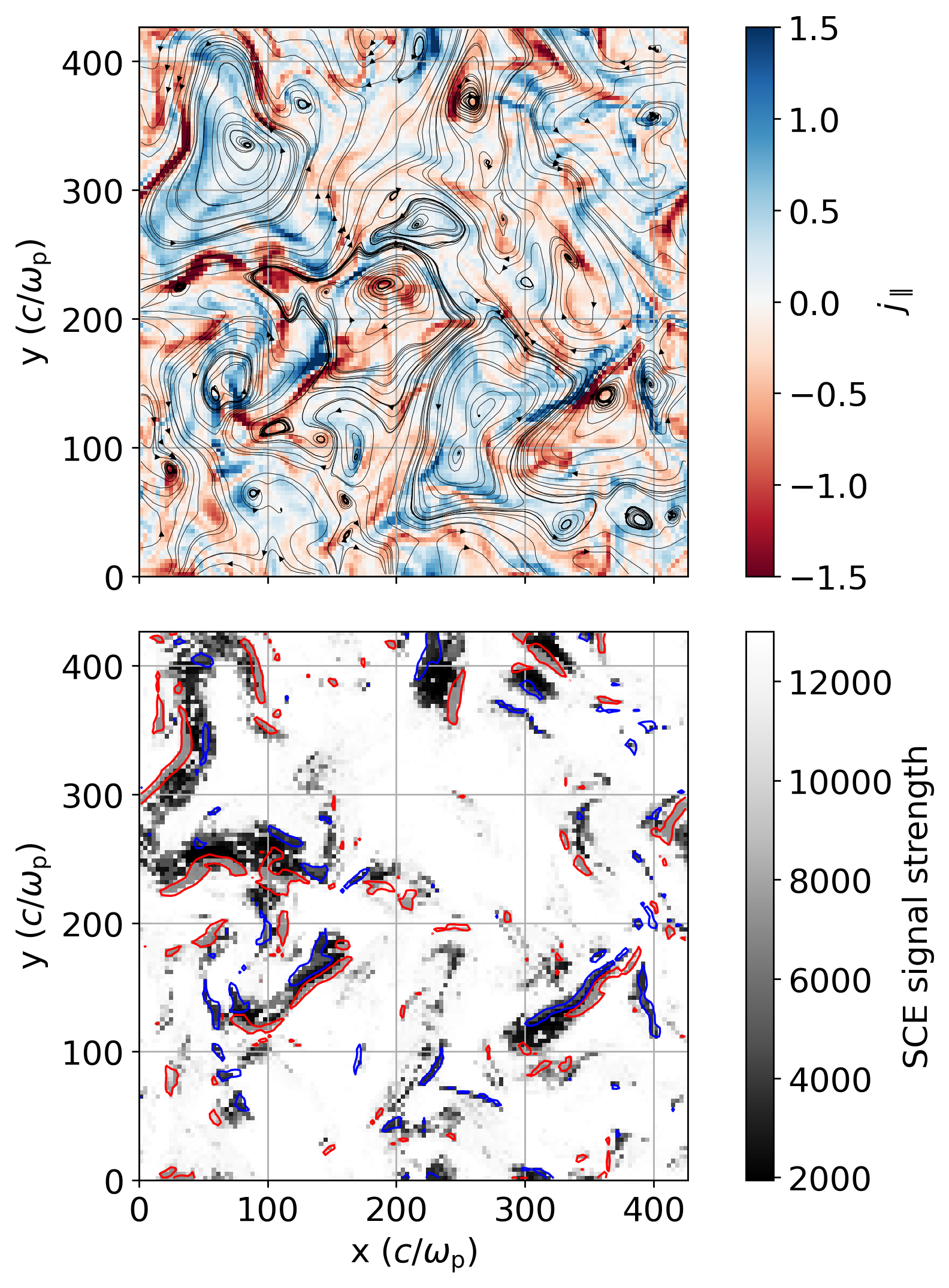
Let’s visualize the distribution of these SCE signal strengths
[ ]:
plt.rcParams.update({'font.size': 14})
plt.figure(dpi=200)
plt.hist(sce_sum, bins=20, color='r', label='SCE Cluster Sum', histtype='step', linewidth=2)
plt.xlabel('SCE Cluster Sum')
plt.ylabel('Frequency')
plt.yscale('log')
plt.show()
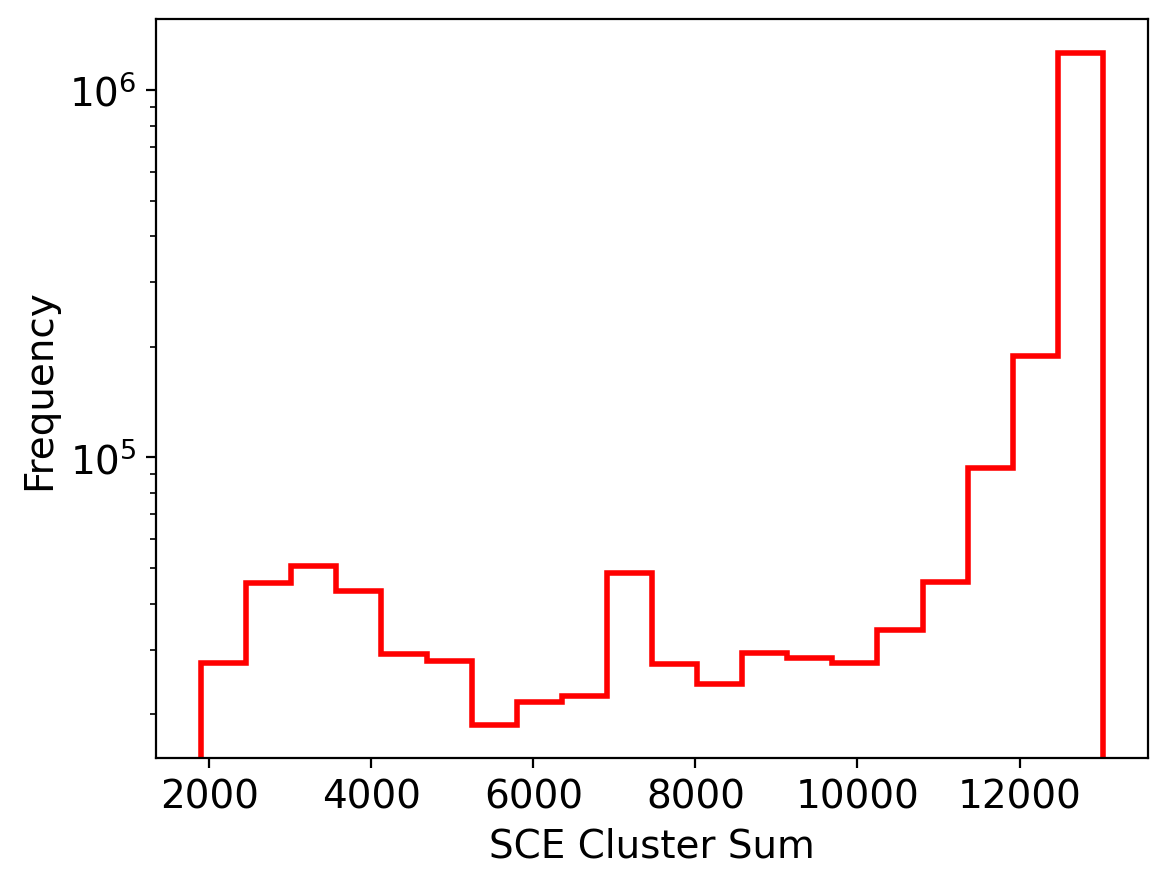
Set a cutoff
[ ]:
signal_cutoff = [3500, 6000, 10000]
sce_clusters = np.zeros(number_of_points, dtype=int)
for i in range(len(sce_sum)):
if sce_sum[i] < signal_cutoff[0]:
sce_clusters[i] = 0
elif sce_sum[i] < signal_cutoff[1]:
sce_clusters[i] = 1
elif sce_sum[i] < signal_cutoff[2]:
sce_clusters[i] = 2
else:
sce_clusters[i] = 3
[ ]:
sce_clusters_transformed = sce_clusters.reshape((128,128,128))
plt.rcParams.update({'font.size': 16})
slice_numbers = [27]
for slice_number in slice_numbers:
fig, ax = plt.subplots(2, 1, figsize=(10, 10), dpi=250, sharex=True)
fig.subplots_adjust(hspace=0.1)
jmag_plot = ax[0].pcolormesh(j_par[slice_number], cmap='RdBu', clim=[-1.5,1.5], rasterized=True)
fig.colorbar(jmag_plot, ax=ax[0], fraction=0.042, pad=0.05, label=r'$j_{\parallel}$', ticks=[-1.5, -1, -0.5, 0, 0.5, 1, 1.5], location="right")
# ax[0].contour(np.arange(0, nx)+0.5, np.arange(0, ny)+0.5, j_par[slice_number,:,:], levels=[-2.*j_par_rms,2.*j_par_rms], colors='green', linewidths=1, linestyles='solid')
ax[0].streamplot(np.arange(0, nx)+0.5, np.arange(0, ny)+0.5, bx[slice_number], by[slice_number], color='black', linewidth=0.25, broken_streamlines=False, density=1., integration_direction='both', arrowstyle='-|>', arrowsize=0.6, )
# fig.colorbar(eperp_plot, ax=ax[0], fraction=0.042, pad=0.04, label=r'$E_{\perp}$', ticks=[0, 0.1, 0.2, 0.3])
ax[0].set_aspect('equal', adjustable='box')
ax[0].grid()
# ax[0].set_xticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
ax[0].set_yticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
# ax[0].set_xlabel(r'x ($c/\omega_p$)')
ax[0].set_ylabel(r'y ($c/\omega_{\rm p}$)')
# ax[0].set_title(f'z = {slice_number*dx:.0f} '+ r'$c/\omega_{\rm p}$')
cluster_plot = ax[1].pcolormesh(sce_clusters_transformed[slice_number], cmap='tab10', clim=[0,10], rasterized=True)
cbar = fig.colorbar(cluster_plot, ax=ax[1], fraction=0.042, pad=0.05, label='Cluster', ticks=np.arange(0, len(signal_cutoff)+1)+0.5, boundaries=np.arange(0, len(signal_cutoff)+2), location="right")
cbar.ax.set_yticklabels(np.arange(0, len(signal_cutoff)+1))
# ax[1].contour(np.arange(0, nx)+0.5, np.arange(0, ny)+0.5, j_par[slice_number,:,:], levels=[-2.*j_par_rms,2.*j_par_rms], colors=['red','blue'], linewidths=1, linestyles='solid')
# ax[1].streamplot(np.arange(0, nx)+0.5, np.arange(0, ny)+0.5, bx[slice_number], by[slice_number], color='black', linewidth=0.25, broken_streamlines=False, density=1, integration_direction='both', arrowstyle='-|>', arrowsize=0.6, )
ax[1].set_aspect('equal', adjustable='box')
ax[1].grid()
ax[1].set_xticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
ax[1].set_yticks(np.arange(0, 128, 30), np.arange(0, 128*dx, 30*dx, dtype=int))
ax[1].set_xlabel(r'x ($c/\omega_{\rm p}$)')
ax[1].set_ylabel(r'y ($c/\omega_{\rm p}$)')
plt.show()
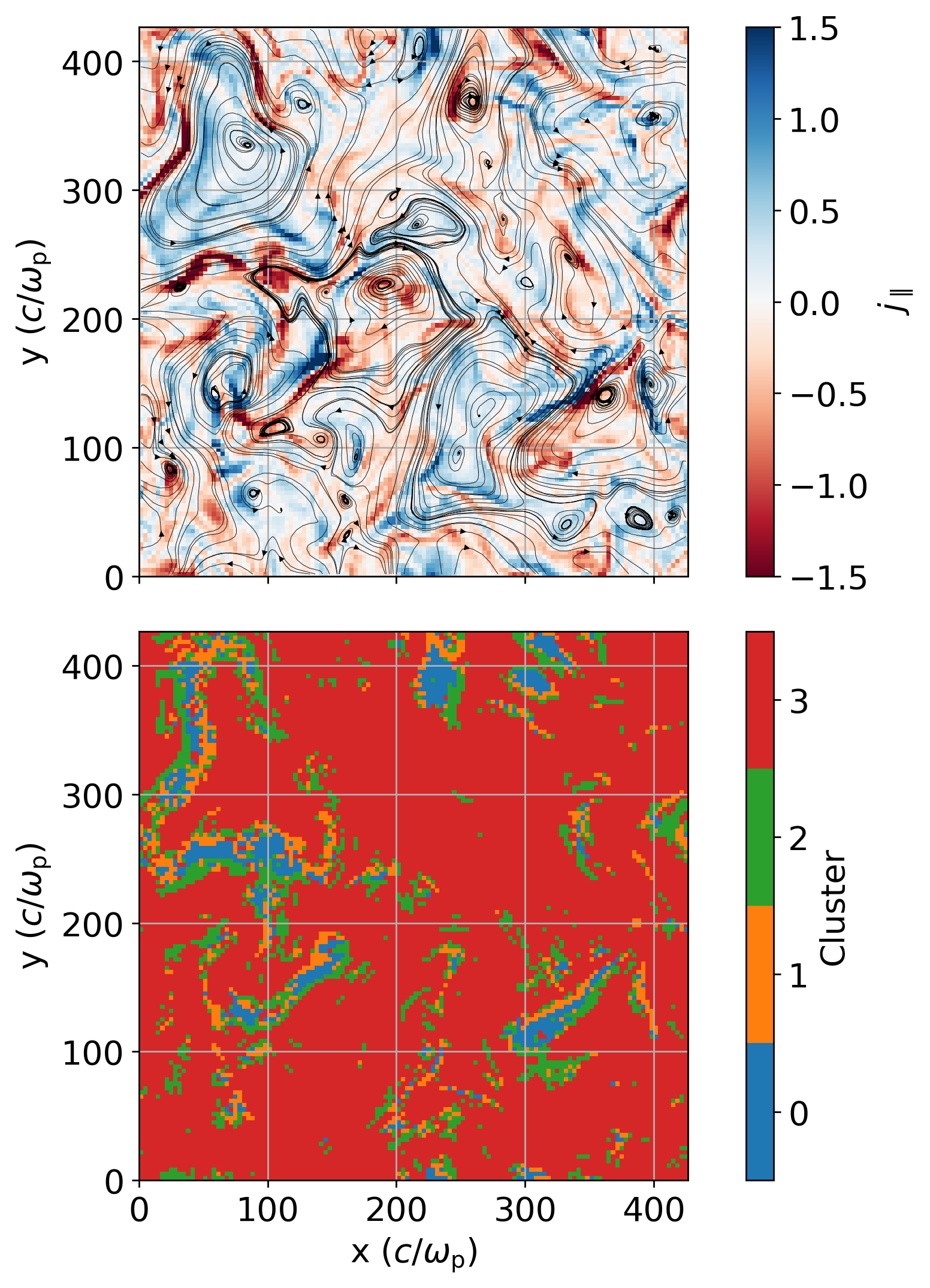
Optional - Generate different sets of features
Under Construction